Part 3: Deployment Strategies, Progressive Delivery, and Blast Radius Control

Most outages in production don’t happen because code is bad.
They happen because change is poorly introduced.
At scale, deployment is not a technical step , it’s a risk management discipline.
This post focuses on how AWS DevOps systems introduce change safely, control blast radius, and recover fast when things go wrong - concepts that sit at the core of both real-world production and the AWS DevOps Professional exam.
Why Deployments Are the Most Dangerous Moment in Production
In stable systems, most of the time:
Traffic patterns are predictable
Infrastructure is healthy
Dependencies are stable
Deployments break that equilibrium.
Every deployment introduces:
New code paths
New infrastructure state
New failure modes
DevOps maturity is measured by how little damage a deployment can do.
The goal is not zero failures —> it’s bounded failures.
Blast Radius: The Most Important DevOps Concept Nobody Talks About
Blast radius is the maximum impact a single failure can cause.
Architect-level DevOps systems intentionally design to:
Limit how many users are affected
Limit how long failures persist
Limit how hard rollback is
If a single bad deploy can take down:
All users
All regions
All services
You don’t have a deployment strategy —> you have a gamble.
Deployment Strategies on AWS (Beyond the Textbook)
1. All-at-Once Deployments (And Why They Fail at Scale)
All-at-once deployments:
Update everything simultaneously
Provide fast feedback
Have maximum blast radius
They are acceptable only when:
Systems are non-critical
Rollback is trivial
User impact is negligible
In production-grade AWS systems, this is usually a last resort, not a default.
2. Rolling Deployments: Controlling the Pace of Change
Rolling deployments:
Replace instances incrementally
Maintain partial capacity during deploys
Reduce sudden load spikes
On AWS, this is commonly implemented using:
Auto Scaling Groups
ECS rolling updates
EKS rolling pod replacements
Trade-offs:
Mixed versions coexist temporarily
Backward compatibility becomes mandatory
Debugging can be harder
Rolling deployments reduce risk —> but they don’t eliminate it.
3. Blue/Green Deployments: Clean Separation of Risk
Blue/Green deployments maintain:
Blue = current production
Green = new version
Traffic is shifted deliberately.
AWS-native implementations:
ALB listener rules
Route 53 weighted routing
Elastic Beanstalk blue/green
ECS + ALB target groups
Key advantages:
Near-instant rollback
Clean environment isolation
No mixed-version state
The cost:
Double infrastructure
More orchestration complexity
For mission-critical systems, this trade-off is usually worth it.
4. Canary Deployments: Learning Before Committing
Canary deployments answer one question:
“Is this safe for everyone?”
Traffic is released gradually:
1%
5%
10%
50%
100%
AWS services enabling canaries:
CodeDeploy
AppConfig
Lambda traffic shifting
ALB weighted target groups
CloudWatch alarms for automated rollback
Canaries turn deployments into experiments:
Observe metrics
Compare behavior
Roll back automatically if impact exceeds thresholds
This is DevOps at its most mature.
Progressive Delivery Is a System, Not a Feature
Progressive delivery combines:
Canary deployments
Feature flags
Real-time observability
Automated decision-making
Key idea:
Decouple deployment from release
With feature flags:
Code can be deployed but disabled
Behavior can be changed without redeploying
Rollback becomes a config change, not a pipeline run
AWS tools commonly involved:
AppConfig
Parameter Store
Secrets Manager
Custom feature flag services
This dramatically reduces deployment pressure.
Observability Drives Deployment Safety
You cannot deploy safely if you cannot observe impact quickly.
Production-grade deployment metrics include:
Error rate deltas
Latency percentiles (p95, p99)
Saturation indicators
Business metrics (checkout success, signups)
CloudWatch alarms during deployment are not optional —> they are guardrails.
A deployment without automated rollback conditions is incomplete.
Exam Insight: What AWS DevOps Professional Is Really Testing
The exam is not asking:
“Do you know what blue/green means?”
It’s asking:
Which strategy minimizes blast radius for this system
How to automate rollback safely
How to balance cost vs safety
When human approval is necessary
When automation should decide
Most correct answers involve:
Progressive traffic shifting
Metrics-driven rollback
Isolation between versions
Minimal user impact
Think in failure containment, not feature delivery.
Production Reality Check
In real systems:
Some deployments will fail
Some metrics will spike
Some rollbacks will trigger incorrectly
The question is not if —> it’s how controlled the outcome is.
A mature AWS DevOps system:
Assumes deployments will break things
Limits how much they can break
Recovers faster than users notice
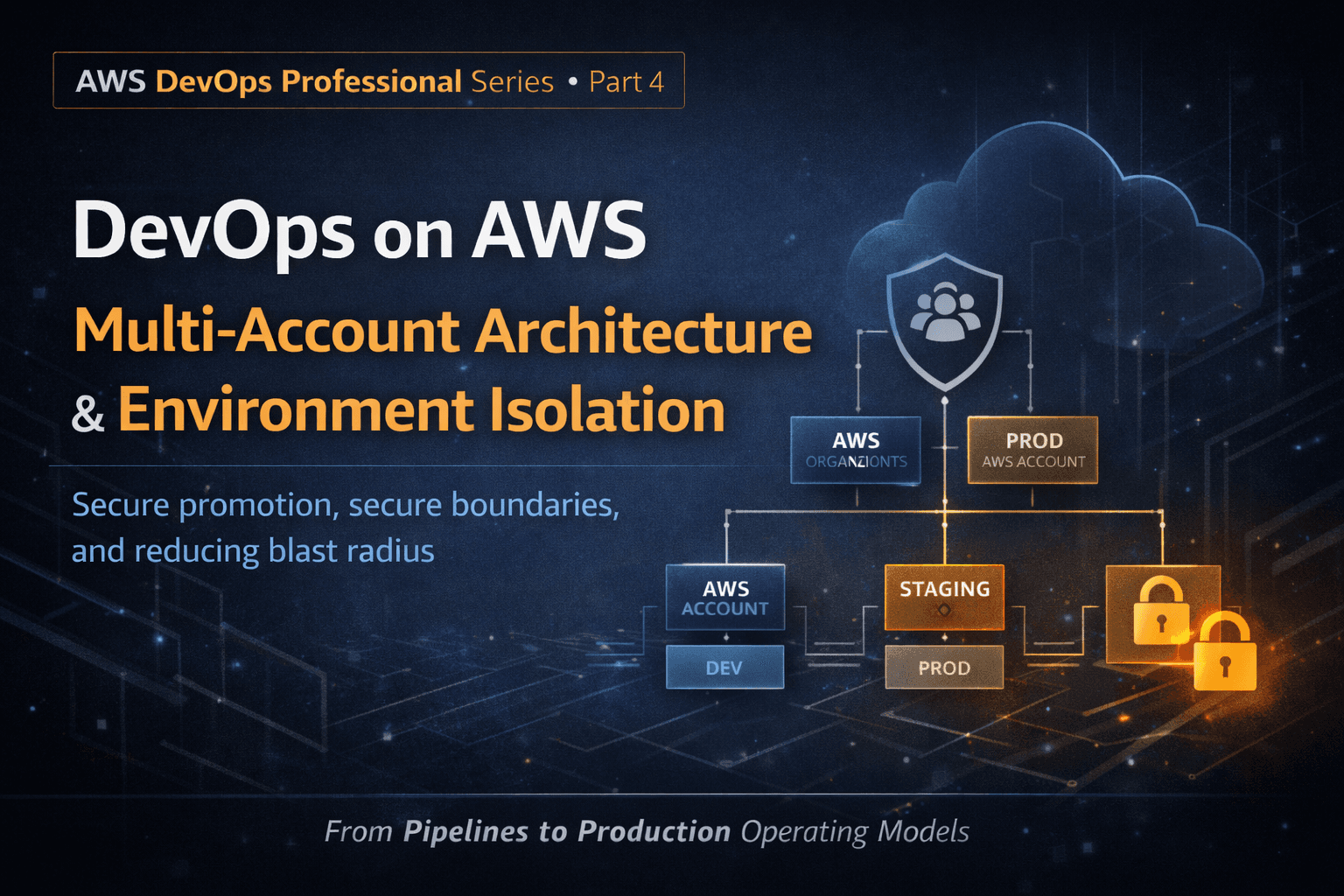
What’s Next (Part 4)
In Part 4, we’ll dive into:
Multi-Account DevOps & Environment Isolation
Why single-account DevOps fails at scale
AWS Organizations and account boundaries
CI/CD across dev, staging, prod
Secure promotion pipelines
Reducing blast radius at the account level
Final Thought
Deployments are not about speed.
They are about confidence under uncertainty.
AWS DevOps Professional is about designing systems where change is routine, not terrifying.